
ATAlign 是一款 Windows 本地运行 的 音文对齐(Audio-Text Alignment) 工具,将音频与对应文本进行音文对齐、时间轴匹配,自动生成 字幕文件(SRT/VTT/ASS),并支持导出 字级时间戳 JSON。
最新版本
- v1.3
- 更新内容:
- 修复BUG:音文对齐结束越界错误!
- 更新方法:老版本用户直接从网盘下载CPU/GPU版本的exe主程序替换即可,不需要重新下载.7z全量压缩包;
0.视频教程
https://www.bilibili.com/video/BV17Q6JBDEqG/
1. 软件简介
ATAlign(音文对齐工具) 基于深度学习与强制对齐技术(Forced Alignment),将音频内容与文本内容精准对齐到时间轴,自动生成字幕与时间戳数据。
核心功能(关键词:音文对齐 / 时间戳 / 字幕生成)
-
自动对齐:基于 CTC(Connectionist Temporal Classification)强制对齐
-
多模型支持:
standard-Multi(多语言标准)与large-zh(中文高精度) -
多格式输出:SRT / VTT / ASS + JSON 字级时间戳
-
CPU/GPU 加速:支持 CPU 加速与 NVIDIA GPU 加速(需设备与驱动支持)
-
批量处理:批量导入音频,队列依次处理(VIP/永久 VIP)
-
拖放导入:音频文件可直接拖入任务列表
适用场景
-
TTS文本转语音后无字幕场景下的后期字幕制作(音频干净,无背景噪声)
注意:
-
不适用于背景嘈杂的音频,如歌曲音乐等
2. 系统要求
本软件提供 全量版(支持 CPU+GPU) 与 CPU 专用版 两个版本,请根据您的硬件环境选择合适的版本。
版本说明
-
全量版:体积较大,内置 GPU 加速组件。支持 NVIDIA 显卡加速,若无显卡也可自动降级使用 CPU 运行。
-
CPU 专用版:体积较小,精简了 GPU 相关组件,仅支持 CPU 运行。适用于没有独立显卡的办公电脑或轻量化环境。
运行环境要求
最低配置(基础运行)
适用于 CPU 专用版 或 全量版(CPU模式):
| 项目 | 要求 |
|---|---|
| 操作系统 | Windows 10/11 64 位 |
| 处理器 | Intel Core i5 8代 / AMD Ryzen 3000 系列或同等性能(需支持 AVX2 指令集) |
| 内存 | - 基础模型 (standard-Multi):8 GB RAM - 高精度中文模型 (large-zh):建议 16 GB RAM |
| 硬盘空间 | 至少 5 GB 可用空间(SSD 固态硬盘建议,大幅提升模型加载速度) |
| 显卡 | 集成显卡或任意亮机卡 |
推荐配置(高性能加速)
适用于 全量版 且拥有 NVIDIA 显卡 的用户:
| 项目 | 要求 |
|---|---|
| 操作系统 | Windows 10/11 64 位 |
| 处理器 | Intel Core i7 / AMD Ryzen 7 或更高 |
| 内存 | 16 GB RAM 或更高 |
| 硬盘空间 | 10 GB 可用空间(SSD 强烈推荐) |
| 显卡 | NVIDIA GeForce GTX 1060 6GB 及以上 |
| 显存 | 建议 6GB 或更高(显存不足可能导致大模型加载失败) |
| 驱动 | 必须安装最新的 NVIDIA 官方驱动(Studio 或 Game Ready 版本) |
特别说明:
AMD 或 Intel 显卡:目前暂不支持 GPU 加速,请直接使用 CPU 专用版。
老旧显卡:若您的显卡架构较老(如 Maxwell 架构以前),可能无法支持最新加速库,建议使用 CPU 模式。
3. 安装与启动
-
下载软件压缩包
-
解压到任意目录(建议路径不包含中文和空格)
-
双击运行
ATAlign.exe
首次启动与登录
首次启动会显示登录界面,请使用网站账号登录(没有账号可先注册一个)
注意:同一账号不支持重复登录,后登录账号会将先登录账号挤下线!
4. 界面介绍
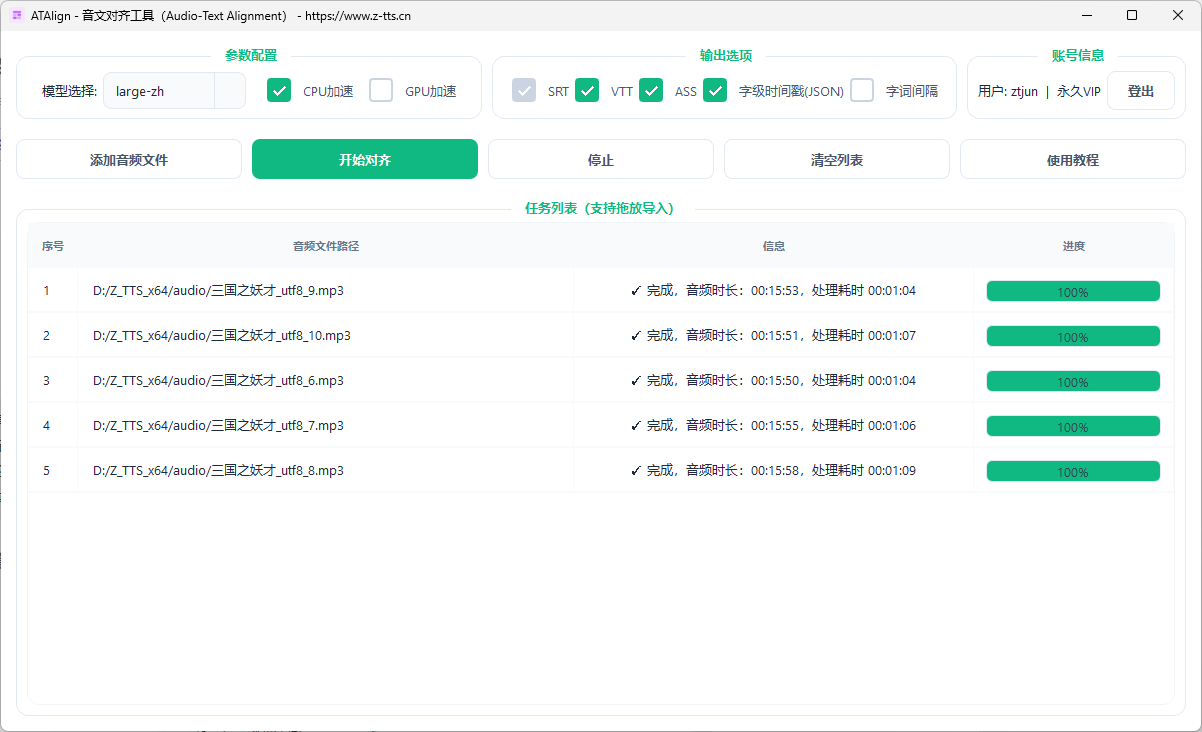
软件主界面一般分为:
-
参数配置:模型选择、CPU 加速、GPU 加速
-
输出选项:SRT / VTT / ASS / 字级时间戳 JSON(根据会员等级显示可选项)/字词间隔
-
账号信息:用户名、会员等级、登出
-
任务区:添加音频、开始对齐、停止、清空列表、使用教程
-
任务列表:支持拖放导入与进度显示
5. 快速上手(3 分钟学会字幕生成)
步骤 1:准备文件(关键词:同名文本 / UTF-8 / 音频转字幕)
确保音频与文本满足:
-
音频:
.mp3/.wav -
文本:
.txt,UTF-8 编码,文本内容需与音频内容保持一致 -
命名:音频与文本同名(仅扩展名不同)
示例:
C:\音频项目\ ├── 第一章.mp3 ├── 第一章.txt ├── 第二章.mp3 └── 第二章.txt
步骤 2:导入音频
-
点击「添加音频文件」选择音频
-
或直接将音频拖放到任务列表区域(拖放导入)
普通会员一次仅处理 1 个任务;VIP/永久 VIP 可批量加入队列处理(详见第 6.4 节)。
步骤 3:配置选项(关键词:Multi / large-zh / CPU加速 / GPU加速)
| 选项 | 说明 | 建议 |
|---|---|---|
| 模型选择 | standard-Multi 为多语言标准模型;large-zh 为中文高精度模型 |
普通会员选择 standard-Multi;中文高精度建议用 large-zh(VIP/永久) |
| CPU 加速 | CPU 推理加速(对 CPU 模式有效,轻微损失精度,提升速度) | 建议开启 |
| GPU 加速 | NVIDIA GPU 推理加速(需硬件支持) | 有 GPU 建议开启 |
| 输出格式 | SRT/VTT/ASS/JSON | 普通会员仅 SRT;VIP/永久可选更多 |
步骤 4:开始对齐
点击「开始对齐」→ 等待任务完成。
步骤 5:查看结果(字幕文件位置)
字幕默认保存到软件目录下 output 文件夹(以软件提示为准):
软件目录\ └── output\ ├── 第一章.srt ├── 第一章.vtt (若勾选) ├── 第一章.ass (若勾选) └── 第一章.json (若勾选字级时间戳)
6. 详细功能说明
6.1 模型选择:
| 模型 | 特点 |
|---|---|
| standard-Multi | 多语言通用 |
| large-zh | 中文优化,精度更高 |
普通会员仅可使用
standard-Multi模型。
6.2 模型下载与安装
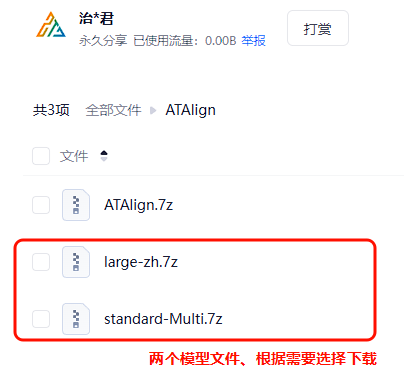
standard-Multi为标准多语言模型
large-zh是经过专门调校的中文模型(网站VIP才可以使用)
- 2、解压缩
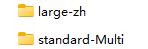
- 3、将解压后的模型文件夹整体移到以下位置
X:\ATAlign\_internal\models_bundle\
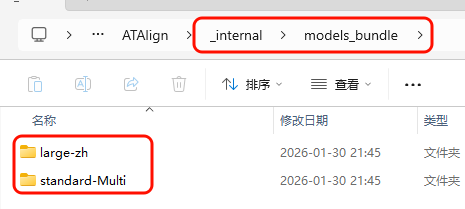
注意:模型文件夹确认只有一层目录,打开large-zh或standard-Multi模型目录可以直接看到模型相关文件,如下图所示:
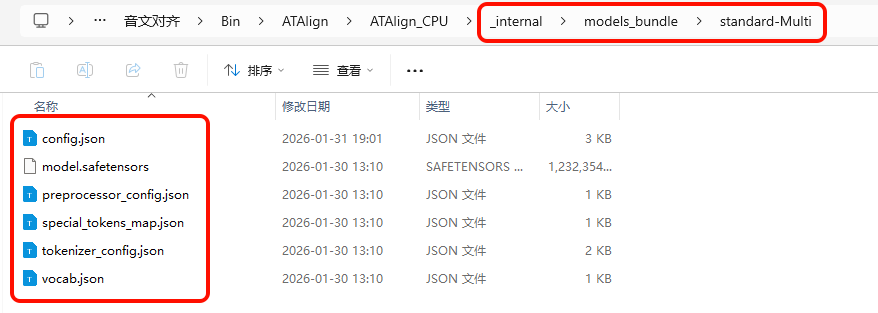
如果模型文件夹下不是模型文件,进行音文识别时会报错:

- 4、重新启动登录ATAlign即可自动加载模型列表
6.3 加速选项
CPU 加速
-
用于提升 CPU 推理速度(通常会更快,具体与机器配置有关)
-
在 CPU 模式下建议开启
GPU 加速
-
需要 NVIDIA CUDA 兼容显卡与驱动
-
相比纯 CPU 通常更快(实际提升幅度与显卡型号/显存/驱动有关)
-
GPU 加速“可用性以软件检测结果为准”,避免用户环境不同导致争议。
6.4 输出选项:字词间隔
-
开启后会保留文本中的空格
-
适合英文等语种(需要空格作为字词间隔)场景
-
中文等字词间不以空格间隔的语种不需要开启
6.5 批量处理
VIP 与永久 VIP 支持批量导入与队列处理:
-
一次选择多个音频文件
-
按顺序依次处理
-
任务列表可查看进度
7. 输出格式说明(SRT / VTT / ASS / JSON 字级时间戳)
7.1 SRT(最通用字幕格式)
兼容性最好,播放器/剪辑软件基本都支持。
1
00:00:01,500 --> 00:00:04,200
这是第一行字幕内容
7.2 VTT(Web 字幕格式)
适合 HTML5 视频与在线平台。
WEBVTT
1
00:00:01.500 --> 00:00:04.200
这是第一行字幕内容
7.3 ASS(高级样式字幕)
支持字体、颜色、位置等样式,更适合专业字幕制作。
7.4 JSON(字级时间戳)
提供每个字符的时间戳数据,可用于逐字高亮、二次开发、精细校对。
[
{"c": "这", "start": 1.50, "end": 1.65, "score": 0.95},
{"c": "是", "start": 1.65, "end": 1.80, "score": 0.92}
]
JSON 字级时间戳仅限永久 VIP 使用。
8. 会员权限说明
| 功能 | 普通会员 | VIP | 永久VIP |
|---|---|---|---|
| SRT 输出 | ✓ | ✓ | ✓ |
| VTT 输出 | ✗ | ✓ | ✓ |
| ASS 输出 | ✗ | ✓ | ✓ |
| JSON 字级时间戳 | ✗ | ✗ | ✓ |
| large-zh 模型 | ✗ | ✓ | ✓ |
| 批量处理(队列) | ✗ | ✓ | ✓ |
| 单日使用次数 | 20 次 | 无限(合理使用) | 无限(合理使用) |
| 单次最大音频时长 | 10 分钟 | 90 分钟 | 无限 |
| CPU 加速 | ✓ | ✓ | ✓ |
| GPU 加速 | ✓* | ✓* | ✓* |
* GPU 加速需设备与驱动支持,实际可用性以软件检测结果为准。
升级会员:https://www.z-tts.cn/user/vip/
9. 常见问题解答(FAQ)
Q1:提示“对应的 .txt 文件不存在”
原因:音频必须有同名 .txt 文本文件。 解决:
-
文本与音频在同一目录
-
文件名完全一致(扩展名不同)
-
文本必须是
.txt格式
Q2:提示“对齐 token 数 != 可发音字符数”
原因:文本与音频不匹配,或文本中包含音频未读出的内容。 解决:
-
检查文本是否与朗读一致(错别字、缺失/多余内容)
-
删除注释、特殊标记等非朗读内容
-
确保 TXT 为 UTF-8
-
尝试缩短音频/文本后重试
Q3:GPU 加速选项无法使用或自动取消
原因:未检测到兼容 NVIDIA GPU 或 CUDA 环境。 解决:
-
确认是否有 NVIDIA 独显
-
更新显卡驱动
Q4:处理速度慢怎么办?
建议:
-
有 NVIDIA 显卡优先启用 GPU 加速
-
CPU 模式启用 CPU 加速
-
分割长音频、关闭其他占用资源程序
Q5:字幕时间不准确/对不上
常见原因:
-
文本与音频不匹配
-
音频质量差(噪声大、多人说话)
-
数字/缩写读法不一致(建议“123”写成“一二三”)
Q6:提示“普通会员每日上限 20 次”
原因:普通(免费)会员每日最多 20 次。
解决:次日重置(以系统/服务器时间为准)或升级会员解除限制。
Q7:软件闪退或启动失败
排查:
-
路径不含中文/特殊字符
-
管理员权限运行
-
安装 VC++ 运行库()
-
杀毒软件误报添加信任
Q8:登录失败或网络错误
排查:
-
网络正常
-
防火墙未拦截
-
关闭代理后重试
-
确认账号密码正确
Q9:字幕文件在哪里?怎么验证同步效果?
字幕文件在 output 文件夹;可用 PotPlayer/VLC 加载字幕验证效果。
Q10:支持哪些语言?
中文最佳;英文良好;日语/泰语基本支持。多语言场景建议使用 standard-Multi。
Q11:TXT 必须用什么编码?
必须 UTF-8。记事本另存为时编码选择“UTF-8”。
Q12:可以直接处理视频吗?
目前仅支持音频(MP3/WAV)。视频请先用 FFmpeg 提取音轨再处理。
评论(2)
我的运行出错了
联系QQ:50711698